Part #1 of a likely infinite part series.
Today’s innovation was figuring out how to manually set the exposure/AEB setting on the camera so images didn’t look frightening washed out when photographed against a traditional black background.
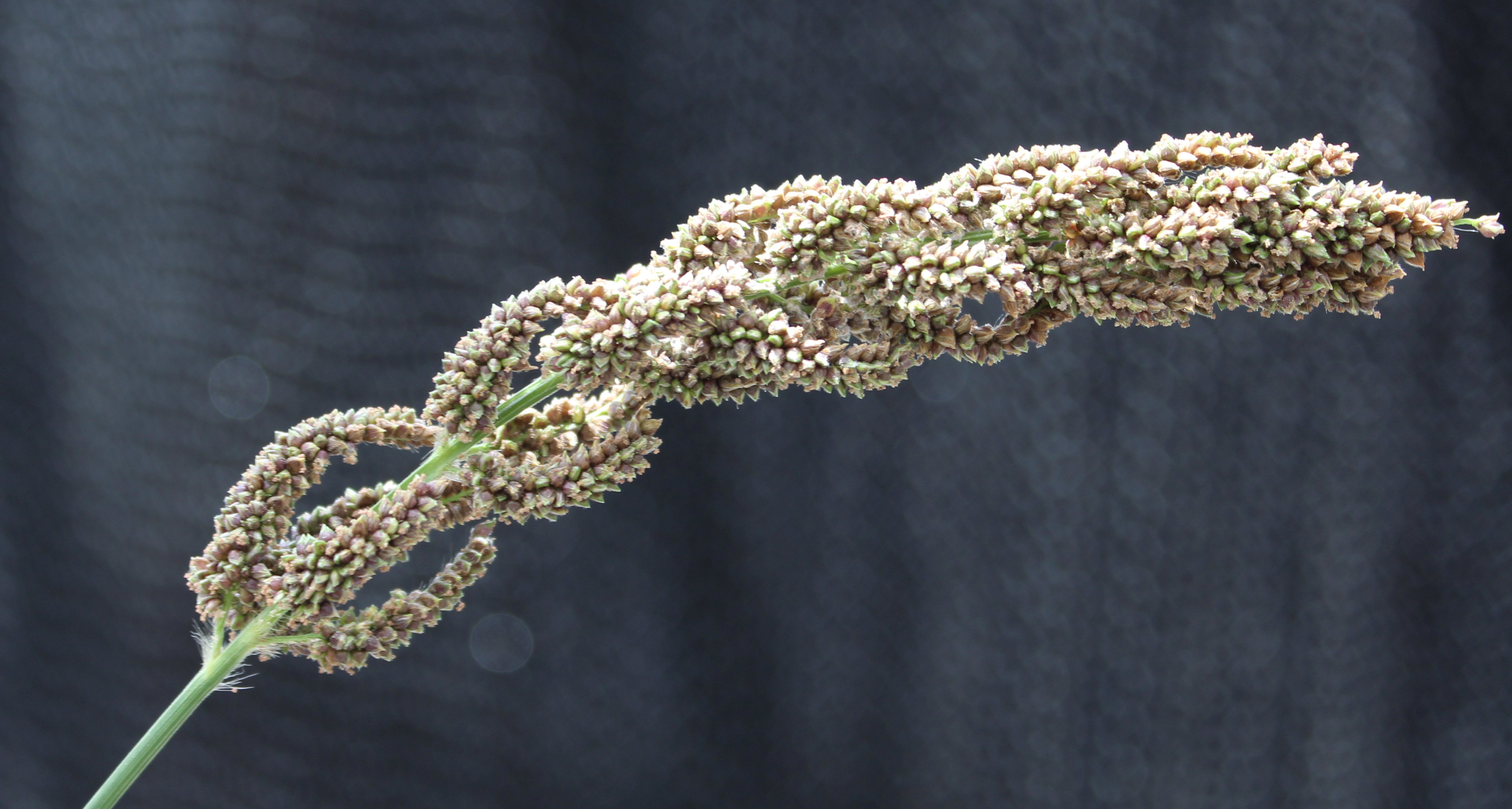
So here’s today’s procrastination figure:

Post-anthesis Setaria italica (foxtail millet)
Of course we really should compare to the wild progenitor, Seteria viridis (Green foxtail). Unfortunately, our Setaria viridis isn’t flowering the greenhouse yet. Fortunately, my tomatillo batch at home is prone to weeds. Unfortunately, I’m not enough of a botanist to code this plant out beyond the genus level. The image below is either Setaria viridis (the direct progenitor of Setaria italica), or (according to the list of grasses native to Nebraska) it could be Setaria faberi, Setaria pumila or Setaria verticillata. I’m reasonably confident it isn’t S. faberi or S. verticillata but S. pumila (Yellow foxtail) is a real possibility. Actually, the more I read about it the more I think this is Setaria pumila given the largish spikelets and tan color of the bristles.

Either Setaria viridis (green foxtail) or Setaria pumila (yellow foxtail). But probably yellow foxtail…
Study of the S. viridis clade also needs to include S. pumila (Poir.) Roem. & Schult., a common weed that often grows in mixed populations with S. viridis and its relatives. Although it appears to be of African origin (Rominger, 2003) and is not closely related to S. viridis in phylogenies (Doust et al., 2007; Kellogg et al., 2009), the ecological preferences of S. pumila are similar to S. faberi and S. viridis (hereafter collectively the “S. viridis clade”).*
So just a tiny bit of DNA sequencing would answer my question once and for all….
In the meantime, I’ll just have to wait for our validated S. viridis plants to flower. Currently twenty one days after planting.

Foxtail millet (Setaria italica genotype Yugu1) on the left hand side and green foxtail (Setaria viridis genotype A10) on the right hand side. Both plants are 21 days old. Note that Yugu1 is significantly taller but unbranched, but the A10 accession of green foxtail has already started producing tillers.
*Daniel J. Layton and Elizabeth A. Kellogg “Morphological, phylogenetic, and ecological diversity of the new model species Setaria viridis (Poaceae: Paniceae) and its close relatives” Am. J. Bot. March 2014 101:539–557 doi: 10.3732/ajb.1300428